Euclidean Distance
The Euclidean distance is the geometric distance we are all familiar with in 3 spatial dimensions. The Euclidean distance is simple to calculate: square the difference in each dimension (variable), and take the square root of the sum of these squared differences. In MATLAB:
% Euclidean distance between vectors 'A' and 'B', original recipe
EuclideanDistance = sqrt(sum( (A - B) .^ 2 ))
...or, for the more linear algebra-minded:
% Euclidean distance between vectors 'A' and 'B', linear algebra style
EuclideanDistance = norm(A - B)
This distance measure has a straightforward geometric interpretation, is easy to code and is fast to calculate, but it has two basic drawbacks:
First, the Euclidean distance is extremely sensitive to the scales of the variables involved. In geometric situations, all variables are measured in the same units of length. With other data, though, this is likely not the case. Modeling problems might deal with variables which have very different scales, such as age, height, weight, etc. The scales of these variables are not comparable.
Second, the Euclidean distance is blind to correlated variables. Consider a hypothetical data set containing 5 variables, where one variable is an exact duplicate of one of the others. The copied variable and its twin are thus completely correlated. Yet, Euclidean distance has no means of taking into account that the copy brings no new information, and will essentially weight the copied variable more heavily in its calculations than the other variables.
Mahalanobis Distance
The Mahalanobis distance takes into account the covariance among the variables in calculating distances. With this measure, the problems of scale and correlation inherent in the Euclidean distance are no longer an issue. To understand how this works, consider that, when using Euclidean distance, the set of points equidistant from a given location is a sphere. The Mahalanobis distance stretches this sphere to correct for the respective scales of the different variables, and to account for correlation among variables.
The mahal or pdist functions in the Statistics Toolbox can calculate the Mahalanobis distance. It is also very easy to calculate in base MATLAB. I must admit to some embarrassment at the simple-mindedness of my own implementation, once I reviewed what other programmers had crafted. See, for instance:
mahaldist.m by Peter J. Acklam
Note that it is common to calculate the square of the Mahalanobis distance. Taking the square root is generally a waste of computer time since it will not affect the order of the distances and any critical values or thresholds used to identify outliers can be squared instead, to save time.
Application
The Mahalanobis distance can be applied directly to modeling problems as a replacement for the Euclidean distance, as in radial basis function neural networks. Another important use of the Mahalanobis distance is the detection of outliers. Consider the data graphed in the following chart (click the graph to enlarge):
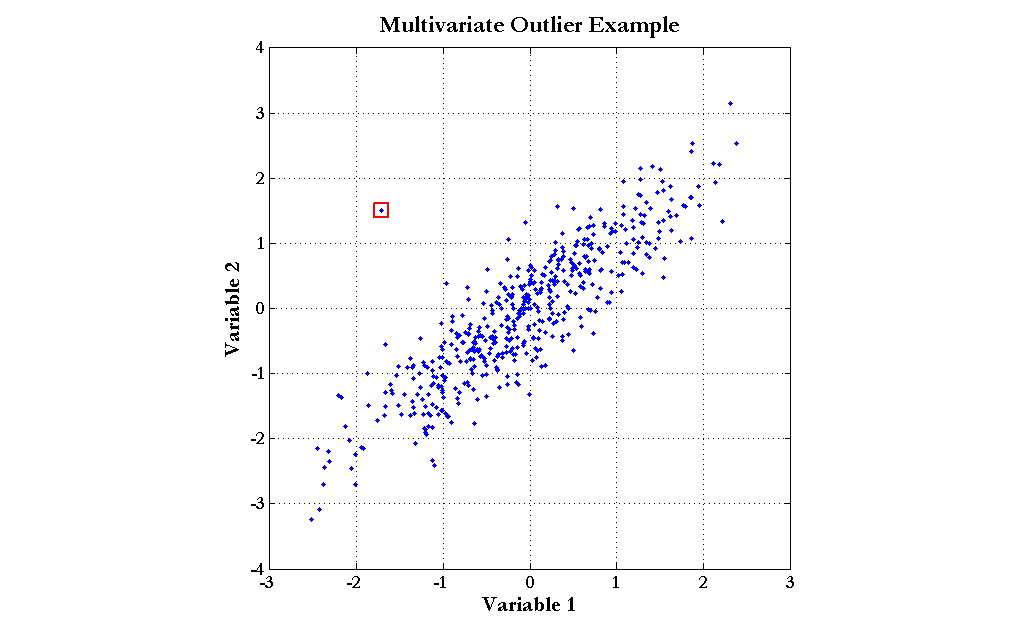
The point enclosed by the red square clearly does not obey the distribution exhibited by the rest of the data points. Notice, though, that simple univariate tests for outliers would fail to detect this point. Although the outlier does not sit at the center of either scale, there are quite a few points with more extreme values of both Variable 1 and Variable 2. The Mahalanobis distance, however, would easily find this outlier.
Further reading
Multivariate Statistical Methods, by Manly (ISBN: 0-412-28620-3)
Random MATLAB Link:
MATLAB array manipulation tips and tricks, by Peter J. Acklam
See Also
Mar-23-2007 posting, Two Bits of Code
31 comments:
thanks from Peru
I'm glad that you found this of interest. This particular post has consistently been one of the most popular on this log, as measured by the number of visits.
Thank you for posting this.
You're welcome, ann!
I have noticed that this is one of the most popular posts I've ever put on here.
I'm curious: What is everyone using the Mahalanobis distance for?
I am using this in conjunction with some Taguchi optimization methods, together called Mahalanobis-Taguchi System (MTS), in automotive applications to understand importance of variables on systems with respect to diagnostics and control. I have coded this all in matlab and wish I would have found this sooner!
-Bill
Thanks for your tutorial!
I am using it for a distance metric in Fisher space (for a face detection project in school).
A colleague of mine is using Mahalanobis distance to evaluate genetic correlations
sorry for disturb..
currently i doing my final year project for my degree..
and i need to noe how to calculate the distance between two objects by using Matlab.
do this Mahalanobis Distance able to help me?
do u have more detail information?
thank you very much!!! tons of appreciation!!! Thank You!
Although not based on the same kind of correlation function, wouldn't you find a N-dimensional distance functon based on Pearson's Correlation (r) to have an approximately equivalent tensor metric without the covariance matrix?
Earl,
Not being familiar with tensors, I could not say.
If (and I may very well be misinterpreting your comment) you are saying that the Pearson correlation taken between points would be equivalent (even approximately) to the Mahalanobis distance,then I don't think that's correct.
Vectors which are exact multiples of each other, for instance, would all have perfect correlation with each other and zero distance. This is not true for Mahalanobis distance.
Can I use it to caclucate distance between text documents
Umar,
Yes, the Mahalanobis distance could be used with text documents, assuming that the text documents could be represented by a number of numeric features.
I suggest examining the literature for "information (or "text" or "document") retrieval" and "spam detection". Also, specifically look into the "bag of words" representation.
In my paper "Comparing Aircraft Agility using Mahalanobis Distances" published in the Journal of Aircraft, I showed how to use the Mahalanobis distance to compare the total agility of different aircraft. For those who don't have MATLAB, just run a multiple linear regression between any two sets of observations, and force the intercept to be zero. This gives a multiple corrrelation coeffeicent that can be used to get D squared. The significance of the distance can be checked using a table of multiple R. Thanks, John R. Howell
Hi Will
I have a simple question (hopefully).
I am currently looking at a problem where I am trying to find the best estimate amongst the many that I found. Each estimate has certain variables associated with it for eg, a frequency, a damping and deflection values (lets say at 5 points, this number can vary). Thus each estimate has these seven quantities associated with it. Each of these seven quantities have different units and scales and more importantly the deflection shape variable can vary in itself depending upon the number of points considered.
The method I was trying to obtain the best estimate was that I calculated the Euclidean distance of each estimate with every other estimate and then sum it up. Whichever estimate has the least sum is chosen as the best estimate.
Now my issues are
1) Since the estimates have variables of different kind and scales, I feel Euclidean Distance might not be the right measure.
2) frequency and damping attribute might always be less heavily weighed in comparison to the deflection shape, as deflection will always have more values associated with it (depending on the number of points chosen).
3) Since these are all estimates of the same quantity, they will all be very similar to each other and thus highly correlated, and going by your definition of Mahalanobis distance, it doesnt seem to be the right measure for this task.
Any comments in this direction are appreciated :)
Thanks in advance
Thank you for your post.
감사합니다 ^^
Thanks for the excellent post. However this link seems not to currently work:
http://www.ee.columbia.edu/~marios/matlab/Matlab%20array%20manipulation%20tips%20and%20tricks.pdf
Mahalanobis distance, by the great P. C. Mahanalobis is a great measure when we are dealing with the exponential family. Furthur, this distance is prone to outliers, it can be robustified using Robust location and scatter estimators. One such estimator is the Minimum covariance determinant.Sadly, oftentimes, the outliers are all pervasive in real data and one has to use robustified estimates in the Mahalanobis.
hi all,
I am using mahalanobis distance.
I found that the covariance matrix is singular and has no singular matrix.
Does anyone have some idea?
Hi Richard, to avoid a singular matrix you can use the pseudo-inverse of the covariance matrix (pinv(cov(data)) instead of the inverse (inv(cov(data)).
Excellent article, thanks.
Am using this one for fraud analysis reporting on a web-based fleet management system. Refueling transactions for vehicles occur over time in a 2-dimensional space (latitude/longitude). Each month the new transactions are compared to the last 12 months worth .. and any new transactions with a mahal distance outside of the norm are flagged for investigation.
Will see if its fast enough to calculate on demand written in PHP. Hope so.
Hi, I am finishing a project. It is exactly as you say on pattern recognition. Given 100 images belonging to 10 classes, and so on. Now I have to calc Mahalanobi's distance and find the smallest. Thanks for your post.
I am using Kohonen Self organizing maps with Mahalanobis distances. Somewhere in my algorithm I need to find the coordinates of the point that is equidistant from two distributions. (with euclidean distances it is the mean of the two distribution centers). Can anyone help with this ? (thanks)
Thanks a million!
thanks! We use it to measure the distances between propensity score distributions in 2 different groups.
Hello, really thanks for your post it is interesting.
I am working in images macthing in distance and I was thinking to use euclidean distance but I read your post and now I feel lost. Could you tell me what advantages can take mahalanobis in my case???
Thanks so much.
Hello, wow your post have done that i change my way to proceed. I am working in matching image in distance, so i was thinking in euclidean distance as a method. then i need to discriminate and say if each point has lees than 3mm take this image as a reference. Coud you tell me what advantages could have mahalanobis in this case?
excellent post....thanks a lot....it really helped me
I like the plain english style, much easier to understand then the wiki-pages. Thank's!
Hello, I would like to know if Mahalanobis distance is 'artificially' increased if dummy variables are used in a regression analysis (using spss) my two out of three categories are entered into a regression and slightly modify tolerance values towards collinearity but not a problem. Thanks
This is great blog. I also developed my own matlab code for mahalanobis distance (with online calculator of mahalanobis distance) in http://people.revoledu.com/kardi/tutorial/Similarity/MahalanobisDistance.html. Hoping you can help to share this.
Hi. I have some questions regarding the Mahalanobis Distance and hope you might be able to help. First - is it usual to calculate Mahalanobis disregarding the covariance matrix? I'm trying to make sense of a program that seemingly does exactly that. Second questions is about the disregard of amount of data sets for calculation. If I try to calculate the overall error of one programm that consists of 4 variables, each with simulated and experimental data. I calculate standard derivation for each of the 4 variables and apply Mahalanobis. Since one of the 4 variables has a large number of experimental measurements and 1 has significantly less, wouldn't Mahalanobis totally disregard the distances in the smaller set if I calculate the total? In RMSE, the average is calculated by devision by n...
Post a Comment