Euclidean Distance
The Euclidean distance is the geometric distance we are all familiar with in 3 spatial dimensions. The Euclidean distance is simple to calculate: square the difference in each dimension (variable), and take the square root of the sum of these squared differences. In MATLAB:
% Euclidean distance between vectors 'A' and 'B', original recipe
EuclideanDistance = sqrt(sum( (A - B) .^ 2 ))
...or, for the more linear algebra-minded:
% Euclidean distance between vectors 'A' and 'B', linear algebra style
EuclideanDistance = norm(A - B)
This distance measure has a straightforward geometric interpretation, is easy to code and is fast to calculate, but it has two basic drawbacks:
First, the Euclidean distance is extremely sensitive to the scales of the variables involved. In geometric situations, all variables are measured in the same units of length. With other data, though, this is likely not the case. Modeling problems might deal with variables which have very different scales, such as age, height, weight, etc. The scales of these variables are not comparable.
Second, the Euclidean distance is blind to correlated variables. Consider a hypothetical data set containing 5 variables, where one variable is an exact duplicate of one of the others. The copied variable and its twin are thus completely correlated. Yet, Euclidean distance has no means of taking into account that the copy brings no new information, and will essentially weight the copied variable more heavily in its calculations than the other variables.
Mahalanobis Distance
The Mahalanobis distance takes into account the covariance among the variables in calculating distances. With this measure, the problems of scale and correlation inherent in the Euclidean distance are no longer an issue. To understand how this works, consider that, when using Euclidean distance, the set of points equidistant from a given location is a sphere. The Mahalanobis distance stretches this sphere to correct for the respective scales of the different variables, and to account for correlation among variables.
The mahal or pdist functions in the Statistics Toolbox can calculate the Mahalanobis distance. It is also very easy to calculate in base MATLAB. I must admit to some embarrassment at the simple-mindedness of my own implementation, once I reviewed what other programmers had crafted. See, for instance:
mahaldist.m by Peter J. Acklam
Note that it is common to calculate the square of the Mahalanobis distance. Taking the square root is generally a waste of computer time since it will not affect the order of the distances and any critical values or thresholds used to identify outliers can be squared instead, to save time.
Application
The Mahalanobis distance can be applied directly to modeling problems as a replacement for the Euclidean distance, as in radial basis function neural networks. Another important use of the Mahalanobis distance is the detection of outliers. Consider the data graphed in the following chart (click the graph to enlarge):
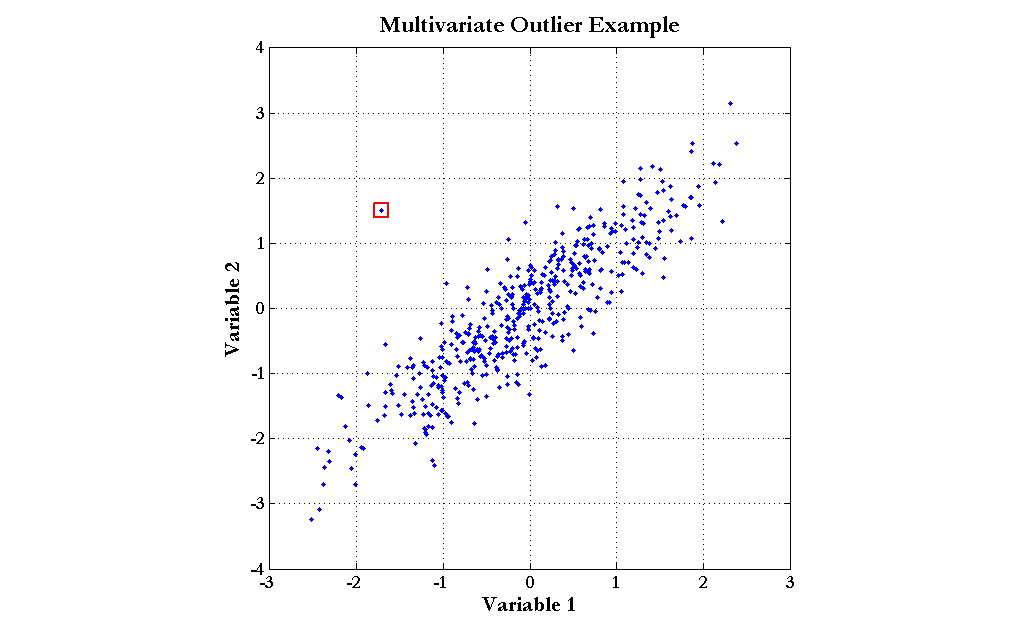
The point enclosed by the red square clearly does not obey the distribution exhibited by the rest of the data points. Notice, though, that simple univariate tests for outliers would fail to detect this point. Although the outlier does not sit at the center of either scale, there are quite a few points with more extreme values of both Variable 1 and Variable 2. The Mahalanobis distance, however, would easily find this outlier.
Further reading
Multivariate Statistical Methods, by Manly (ISBN: 0-412-28620-3)
Random MATLAB Link:
MATLAB array manipulation tips and tricks, by Peter J. Acklam
See Also
Mar-23-2007 posting, Two Bits of Code